102
days / year automated
€85,750
gross ROI / year
5
use cases deployed
7
months of mission
TECHWAVE is an industrial electronics group. For seven months, I sat at the interface between the AI consultancy OPEO and TECHWAVE's engineering and procurement teams — listening to where time was lost, then building Python pipelines to recover it.
Every pipeline runs entirely on-premise. No data leaves the company network. This was a non-negotiable constraint given the confidentiality of client specifications and regulatory documents — and it shaped every architectural decision.

All inference runs on-premise. Zero data leaves the network — and the client never had to trust a third-party API.
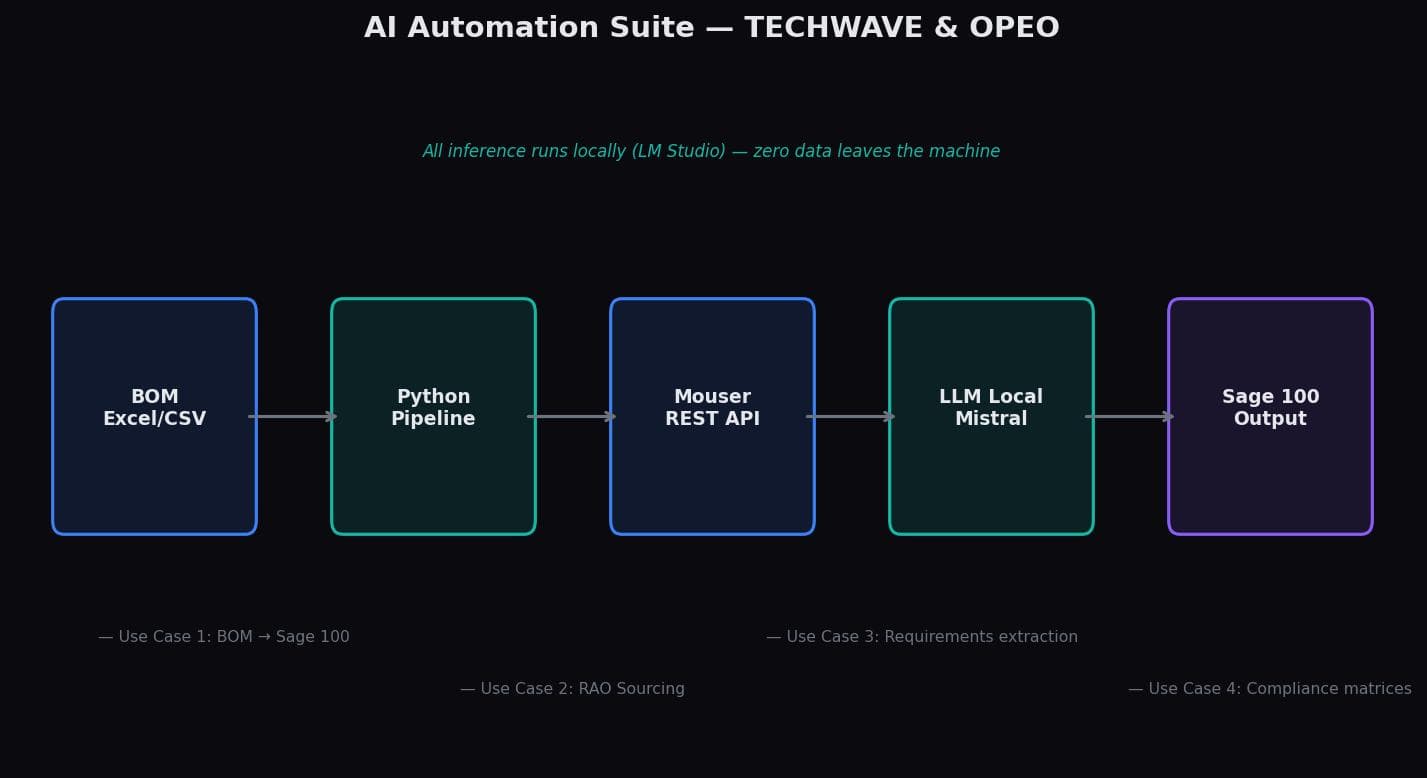
The five use cases
Order processing
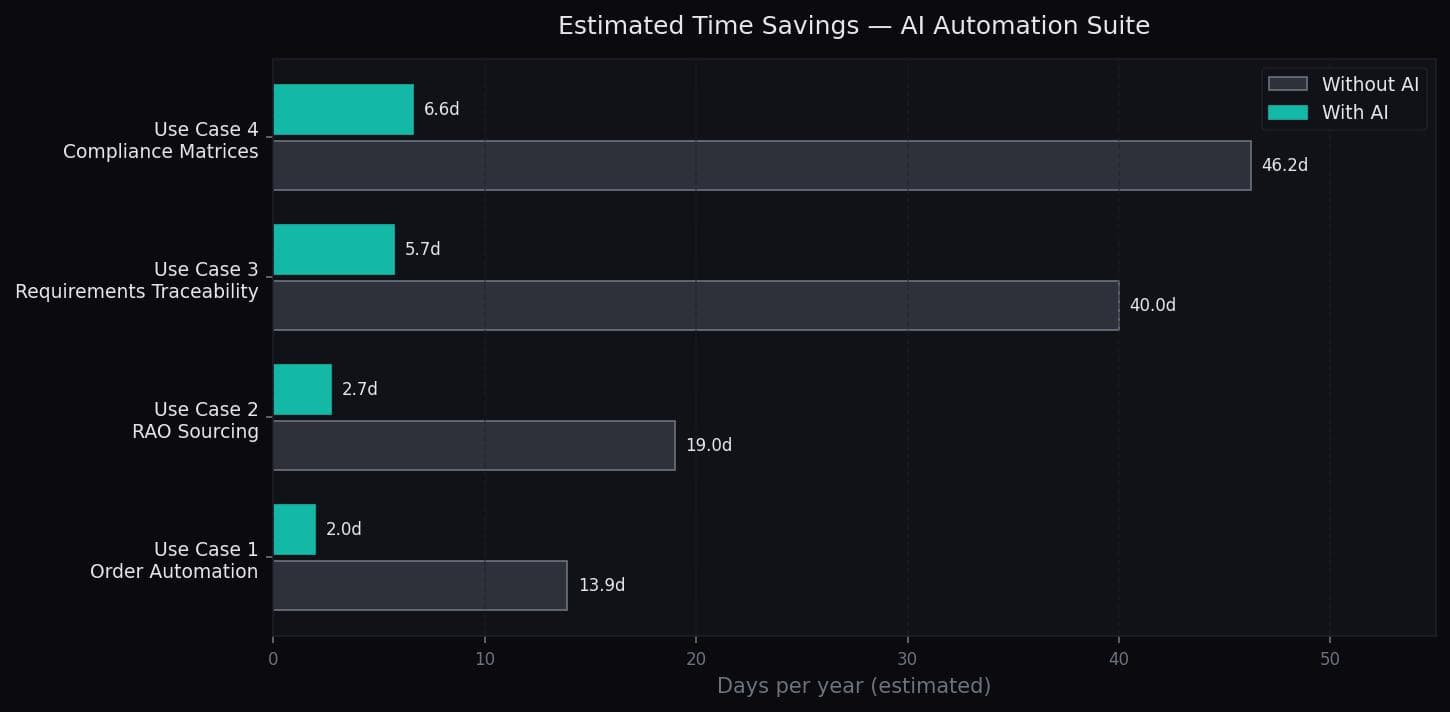
Automated document parsing and entry into Sage 100 ERP. 11.94 days recovered per year from a single pipeline.
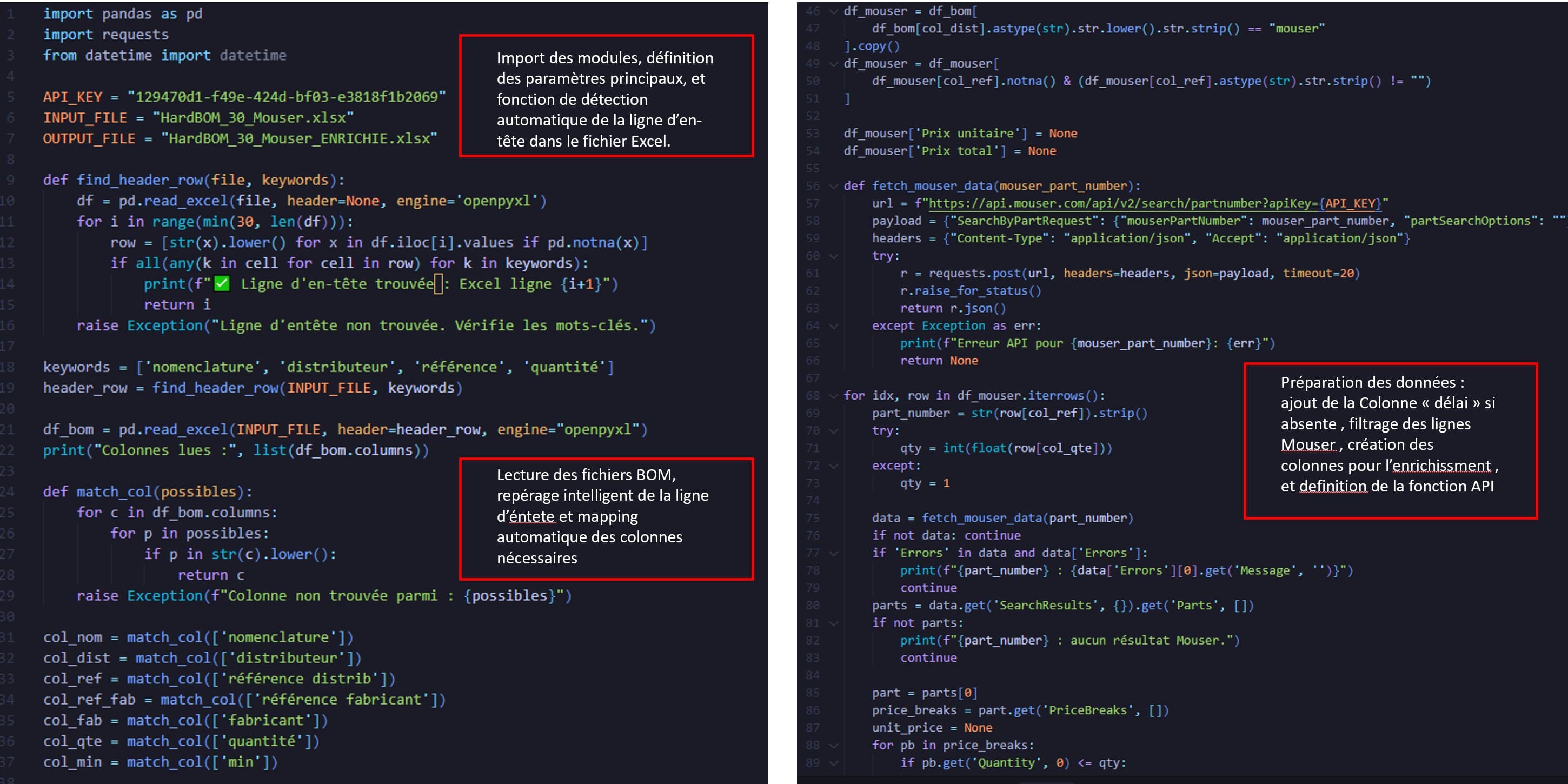
RAO sourcing
Component sourcing from supplier APIs (Mouser, DigiKey). The pipeline detects header rows, maps column names, queries pricing and availability, then exports a formatted Excel ready for import.
BOM update — Refabrication
Bills of materials updated automatically when a refab is triggered. 6 days/year recovered — deceptively simple, but the column-matching logic handles messy real-world files.
Traceability & review
Document review and traceability chains automated. 34.29 days recovered — the largest single gain before compliance.
Regulatory compliance matrices
The most technically complex pipeline. Input: regulatory PDFs (200+ pages). Output: structured compliance matrix with article, description, and classification. 39.64 days recovered per year.
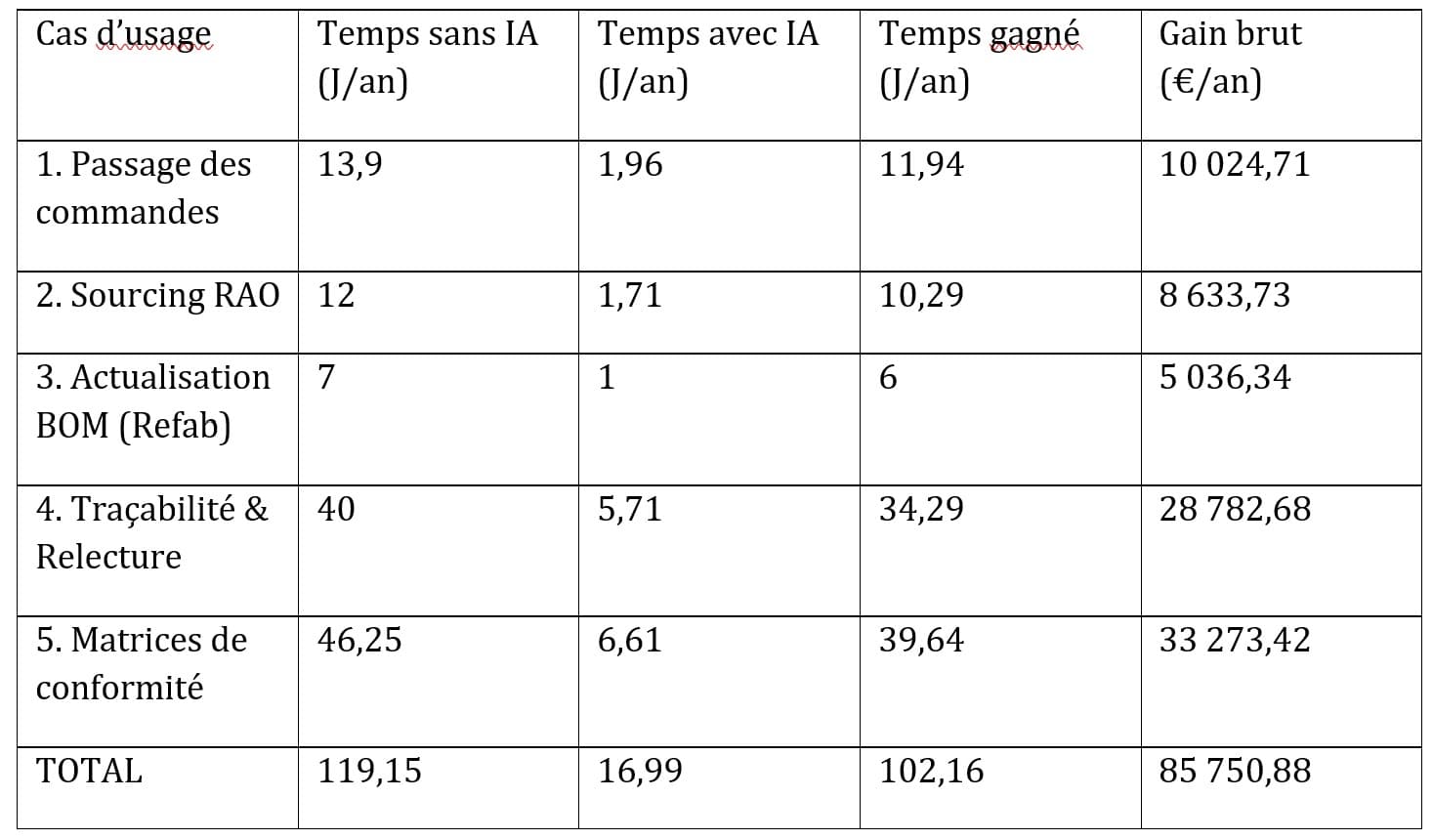
The hardest pipeline: regulatory compliance
Regulatory PDFs are 200+ pages of dense structured text. Three approaches were tested before reaching production.
Rule-based extraction
Deterministic section parsing — fast, but collapses on inconsistent formatting. Too many false positives.
Full LLM extraction
Flexible — the model reads intent, not just structure. But hallucinates on dense regulatory text. Precision too low for production.
Hybrid approach
PyMuPDF handles structure deterministically. LLM only processes ambiguous blocks. Best of both worlds — chosen for production.
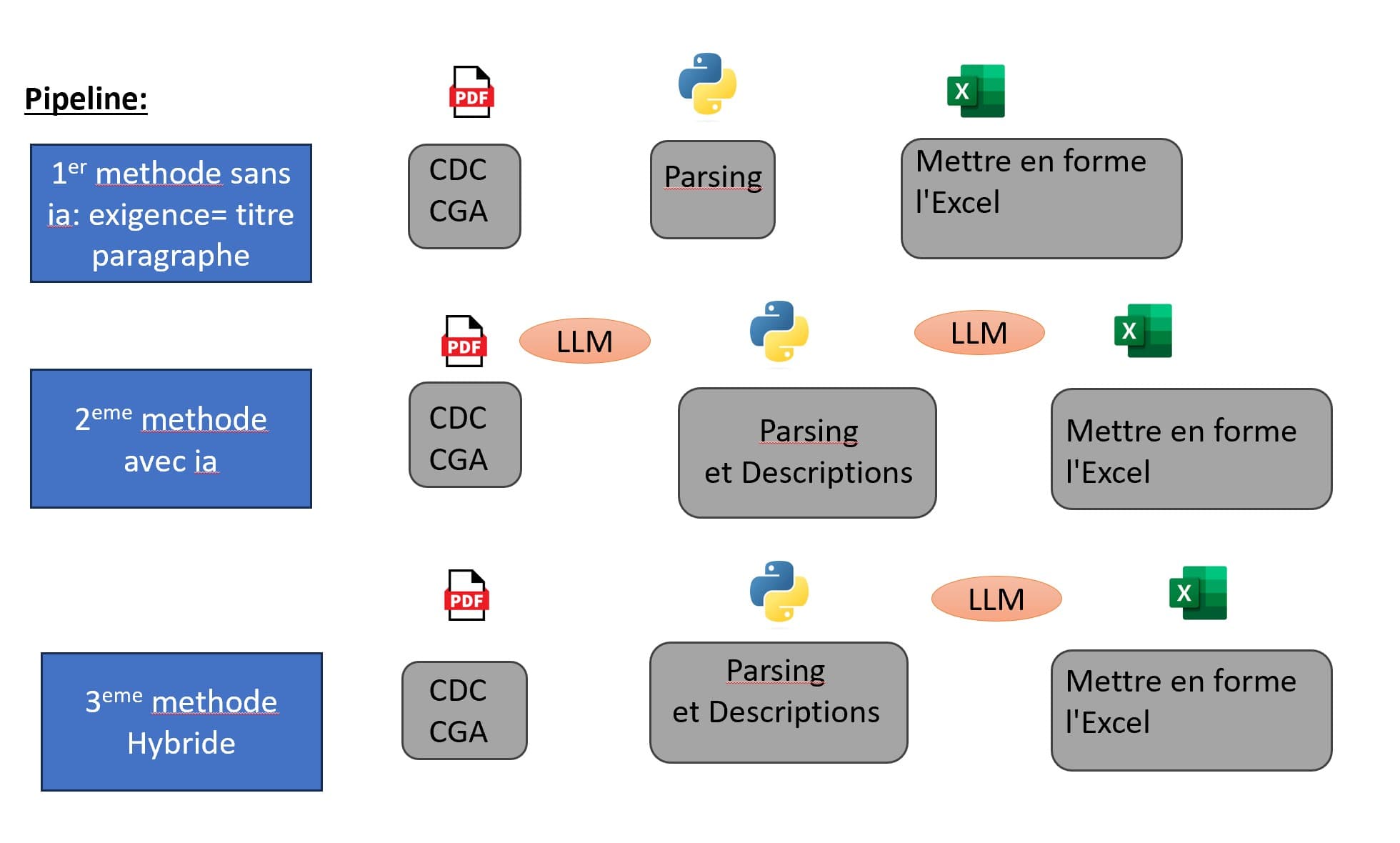




Local LLM infrastructure
All LLM inference runs via Ollama (llama3), wrapped in a TECHWAVE-branded secure chat interface. The system accepts file drag-and-drop, encrypts connections end-to-end, and stores nothing externally. The interface was built to be adopted by non-technical procurement staff.
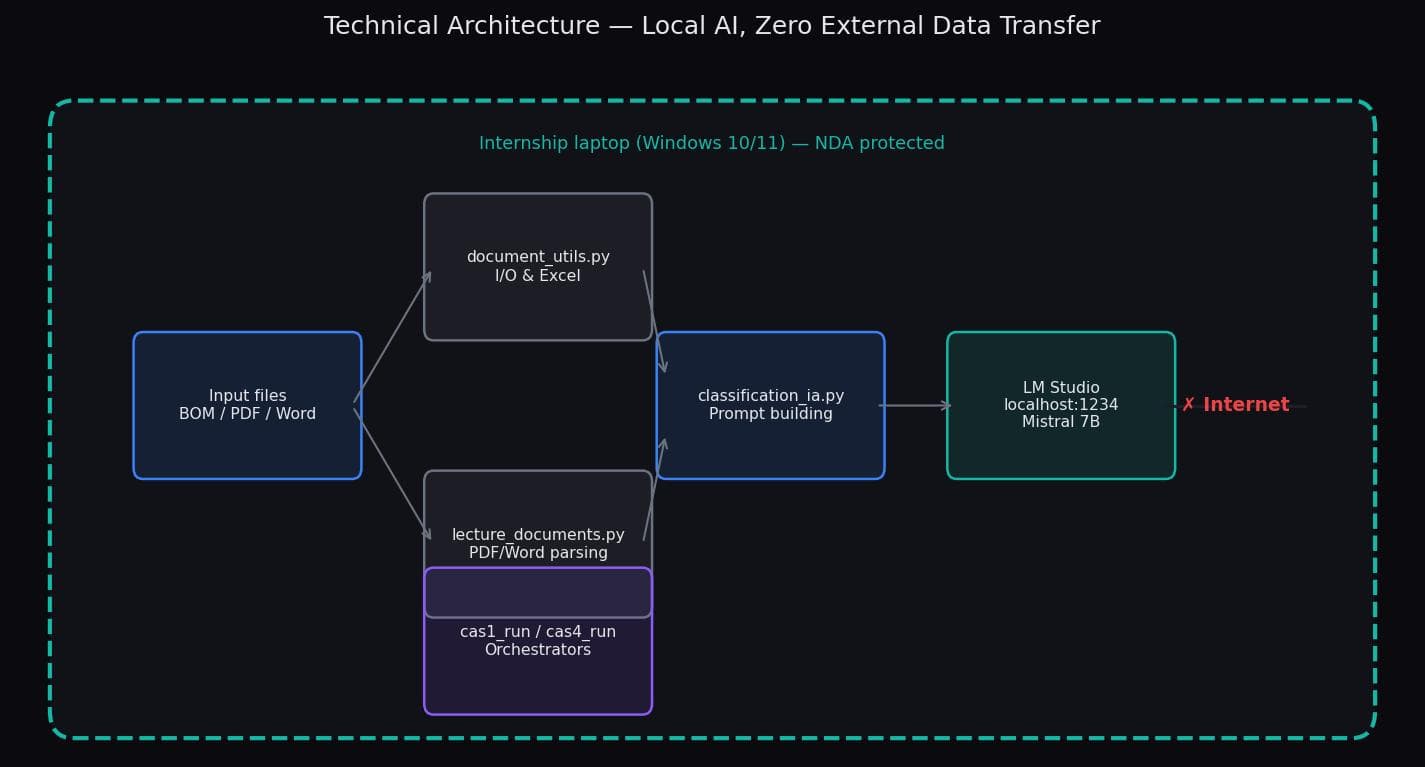
What this demonstrates
This internship was not about applying AI in a sandbox. The pipelines handle real client documents, run in production, and the ROI figures come from TECHWAVE's own time-tracking data. The key engineering decisions — hybrid pipelines, local LLM inference, modular Python architecture — came from real constraints (confidentiality, regulatory precision, staff adoption), not from textbook choices.
Client names, specific document content, and detailed metrics are confidential. Figures shown with permission.